串的定义和实现
串的定义
串是由零个或多个字符组成的有限序列,记为 Ø 表示)
串中任意多个连续的字符组成的子序列称为该串的子串,包含子串的串称为主串
某个字符在串中的序号称为该字符在串中的位置,子串在主串中的位置以子串的第一个字符在主串中的位置来表示
当两个串的长度相等且对应位置的字符都相等时,称这两个串是相等的
串的逻辑结构和线性表极为相似,区别在于串的数据对象限定为字符集。基本操作上线性表操作单个元素,而串操作子串
串的存储结构
定长顺序存储表示
使用一组地址连续的存储单元存储串值的字符序列,这里使用定长数组来为字符串分配位置
#define MAXLEN 255
typedef struct {
char ch[MAXLEN]; // 每个分量存储一个字符
int length; // 串的实际长度
} SString;串的实际长度只能小于等于 MAXLEN,超过预定义长度的串值会被舍去,称为截断
长度由两种表示方法:
- 使用一个额外的变量
len来存储串的长度 - 在串值后面加一个不计入串长的结束标记字符 "\0"
堆分配存储表示
堆分配存储仍以一组地址连续的存储单元存储串值得字符序列,但这组存储单元是动态分配的
typedef struct {
char *ch; // 指向串的基地址
int length; // 串的长度
} HString;在 C 语言中,使用 malloc() 和 free() 函数来实现存储单元的动态管理
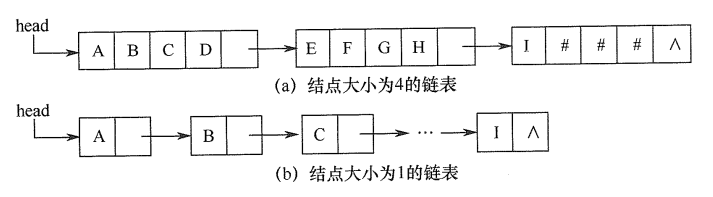
块链存储表示
块链存储类似于线性表的链式存储结构,只不过现在存储的是串值
在具体实现时,每个结点既可以存放一个字符,也可以存放多个字符
每个结点称为块,整个链表称为块链结构
下面是结点大小为 4 的链表和结点大小为 1 的链表,为 4 的链表最后一个结点不满时通常用 "#" 补上
串的基本操作
StrAssign(&T, chars); // 赋值操作
StrCopy(&T, S); // 复制操作,S 复制到 T
StrEmpty(S); // 判空操作
StrCompare(S, T); // 比较操作,S > T 返回 > 0;S = T 返回 0;S < T 返回 < 0
StrLength(S); // 求串长
SubStringg(&Sub, S, pos, len); // 求字串
Concat(&T, S1, S2); // 串连接
Index(S, T); // 定位操作
ClearString(&S); // 清空操作
DestroyString(&S); // 销毁栈上诉操作中,串赋值、串比较、求串长、串连接、求子串五种操作构成串类型的最小操作子集,即这些操作不可能利用其他串操作来实现
其他串操作除串清空和串销毁外,均可在该最小操作子集上实现
串的模式匹配
简单的模式匹配算法
子串的定位操作通常称为串的模式匹配,它求的是字串(常称模式串)在主串上的位置
这里给出顺序存储结构的暴力匹配方法:
int Index(SString S, SString T){
int i = 1, j = 1;
while(i <= S.length && j <= T.length) {
if (S.ch[i] == T.ch[j]) { // 相等比配后面的字符
++i;
++j;
} else { // 主串移动到匹配开始的后一个,模式串回到第一位
i = i - j + 2;
j = 1;
}
}
if (i > T.length) return i - T.length;
else return 0;
}该方式是逐位比较,如果比较不通过那么主串就从比较起点的下一个重新于模式串比较
简单模式匹配算法的最坏时间复杂度为 O(mn),其中 n 和 m 分别是主串和模式串的长度
改进匹配算法:KMP 算法
如果以匹配相等的前缀序列中有某个后缀正好是模式的前缀,那么就可以将模式向后滑动到于这些相等字符对齐的位置,主串 i 指针无须回溯,并从该位置继续比较,如:
1234123412341235 -> 1234123412341235
12341235 -> 12341235
在 5 那里匹配失败,无需回溯主串,只需把模式串右滑 4 位就好了
字符串的前缀、后缀和部分匹配
前缀:指除最后一个字符以外,字符串的所有头部字串
后缀:指除了第一个字符外,字符串的所有尾部字串
部分匹配值:指字符串的前缀和后缀的最长相等前后缀长度
下面以 'abab' 为例:
'a'没有前后缀,最长相等前后缀为 0'ab'前缀为 {a},后缀为 {b},它们交集为空集,最长相等前后缀为 0'aba'前缀为{a,ab},后缀为{ba,a},交集为 {a},最长相等前后缀为 1'abab'前缀为{a,ab,aba},后缀为{bab,ab,a},交集为 {ab},最长相等前后缀为 2
所以字符串 'abab' 的部分匹配值为 0012,将它写成数组形式,就得到部分匹配表(Partial Match, PM)
而子串需要向后移动的位数:移动位数 = 已匹配的字符数 - 对应的部分匹配值
KMP 算法的原理是什么
为什么会有 "移动位数 = 已匹配的字符数 - 对应的部分匹配值" 这个公式呢?下面是我的解释
因为部分匹配值是最大相等前后缀,我们需要将模式串移动到前缀匹配的位置,所以需要少移动最大部分匹配值的长度,也就是把它减掉
对算法进行改进:
对于:移动位数 = 已匹配的字符数 - 对应的部分匹配值
写成:Move = (j - 1) - PM[j - 1],其中 j 是匹配失败的位置,已匹配的字符数是 j - 1
如果我们将 PM 表右移一位,就变成 Move = (j - 1) - next[j],而 'abab' 的表就从 0012 变成 -1001,可以注意到:
- 第一个元素使用 -1 填充,因为第一个元素匹配失败会向右移动一位
- 最后一个元素被消去了,因为最后一个元素没有下一个元素,所以它的部分匹配值就没人使用
而 j - Move 就是移动后的模式串开始比较位置:j - Move = j - ((j - 1) - next[j]) = next[j] + 1
为了更加整洁会直接将 PM 整体加 1,所以 'abab' PM 就会写成 0112,就得到公式 j = next[j]
next[j] 的含义是:在子串的第 j 个字符于主串发送失配时,则跳到子串的 next[j] 位置重新与主串当前位置进行比较
next[j] 也是 [1...j-1] 最大相等前后缀的长度 + 1
next 数组的计算
next[j] 是 [1...j-1] 最大相等前后缀的长度 + 1
而某个位置最大相等前后缀可以写成
又有 next[1] = 0,以及最大前后缀为空时要写成 next[j] = 1
就有
现在就是
使用数学归纳法,假设 next[j] = k 满足上面的条件,那么对于 next[j + 1] = ? 有两种可能:
若
表明 ,由于 next[j] = k 是最大前后缀,所以这里也是最大前后缀 所以 next[j + 1] = k + 1 即 next[j + 1] = next[j] + 1
若
,表示 则需要寻找第二大前后缀 设 q 是第二大前后缀,则它需要满足
很显然第二大前后缀就是 q = next[k],那么就比较
和 如果等于就 next[j] = q + 1,不等就找第三大前后缀 q = next[k],而第三大就是 next[next[k]] 套娃下去直到找到,或者最大前后缀是空集就置 1
如:
'abcabdabcabcabd'在这个粗体 c 这里它是先和 6 对比的然后再与 3 对比,next[12 + 1] = next[3] + 1 = 4
代码实现
void getNext(String T, int next[]) { // 求 next 值
int i = 1, j = 0; // 这里的 j 其实就是 next[k]
next[1] = 0;
while (i < T.length) {
if (j == 0 || T.ch[i] == T.ch[j]) {
++i; ++j;
next[i] = j; // 若 pi = pj,则 next[j + 1] = next[j] + 1
}
else j = next[j]; // 否则令 j = next[j],也就是 next[next[k]]
}
}
int IndexKNP(String S, String T, int next[]) {
int i = 1, j = 1;
while (i <= S.length && j <= T.length) {
if (j == 0 || S.ch[i]) {
++i; ++j; // 继续比较后继字符
}
else
j = next[j]; // 模式串向右移动
}
if (j > T.length)
return i - T.length; // 匹配成功
else
return 0;
}尽管普通模式匹配的时间复杂度是 O(mn),KMP 算法的时间复杂度是 O(m+n),但一般情况下普通模式匹配的实际执行时间近似为 O(m+n),因此至今仍被采用
KMP 算法仅在主串与子串有很多部分匹配时才显得比普通算法快得多,其主要优点是主串不回溯
KMP 算法的进一步优化
前面定义的 next 数组在某些情况下尚有缺陷,还可以进一步优化,如模式 'aaaab' 在和主串 'aaabaaaab' 进行匹配过程不谈
问题在于不应该出现
所以当出现 next[j] 等于 next[next[j]] 的递归形式
void getNextval(String T, int nextval[]) {
int i = 1, j = 0;
nextval[1] = 0;
while (i < T.length) {
if (j == 0 || T.ch[i] == T.ch[j]) {
++i; ++j;
// 就改动了这里,令 pj=pnextj 时 next[j] = next[next[j]]
if (T.ch[i] != T.ch[j]) nextval[i] = j;
else nextval[i] = nextval[j];
}
else
j = nextval[j];
}
}注意:优化后的 KMP 数组改名为 nextval,如果数组名叫 next 是未优化的 KMP
手算 KMP 的 nextval 数组
注意:在实际 KMP 算法中,如果串位序从 1 开始则 next 元素加 1,从 0 开始不需要加 1
需要先计算 next 数组(按照"next 数组的计算"的思路来手算就好了)
置 nextval[1] = 0;i = 2
遍历字符串,比较 S[i] 和 next[i]
相等 nextval[i]=nextval[next[i]]
不相等 nextval[i]=next[i]
