数理统计·1 数理统计的基本概念
考纲内容
- 总体、个体、简单随机样本、统计量、样本均值、样本方差、样本矩
- $\chi^2 $ 分布,$ t$ 分布,
分布,分位数,正态总体的常用抽样分布
脑图
graph TD
A["简单随机样本"]---|不含未知参数的函数|B["统计量"]
B-->C["常用统计量:<br>样本平均值<br>样本方差<br>样本标准差<br>样本 k 阶原点矩<br>样本 k 阶中心矩"]
B-->D["经验分布函数"]
B-->E["χ2 分布"]
B-->T["t 分布"]
B-->F["F 分布"]
N["正态总体的统计量性质"]---B一、随机样本
1. 随机样本诸概念的定义
在数理统计中,我们通常研究某个对象的特定数量指标。例如,研究某种型号灯泡的寿命。为此,我们会进行与这一数量指标相关的随机试验。这些试验的结果值不一定都相同,且其数量也不一定是有限的。
- 每一个可能的观察值称为个体。
- 总体中包含的所有个体的总数称为总体的容量。
根据容量的大小,可以将总体分为:
- 有限总体:容量有限的总体。
- 无限总体:容量无限的总体。
设 $X $ 是具有分布函数 $ F$ 的随机变量。若 $X_1, X_2, \cdots, X_n $ 是具有相同分布函数 $ F$ 的、相互独立的随机变量则称 $X_1, X_2, \cdots, X_n $ 为从分布函数 $ F$(或总体
2. 分位数
定义设有容量为 $n $ 的样本观察值 $ x_1, x_2, \cdots, x_n $,样本 $ p$ 分位数 (
- 至少有 np 个观察值小于或等于
- 至少有 n (1-p) 个观察值大于或等于
显然,
样本
首先,将
若 np 不是整数,则只有一个数据满足定义中的两点要求,这一数据位于大于 np 的最小整数处,即为位于 $[np] + 1 $ 处的数。例如,$ n = 12
p = 0.9 $,则 $ np = 10.8 n (1 - p) = 1.2 $。则 $ x_p$ 的位置应满足至少有 10.8 个数据$\leq x_p x_p$ 应位于第 11 或大于第 11 处);且至少有 1.2 个数据 ( 应位于第 11 或小于第 11 处),故 应位于第 11 处。 若 np 是整数。例如在 $n = 20
p = 0.95 $ 时,$ x_p$ 的位置应满足至少有 19 个数据 $\leq x_p x_p$ 应位于第 19 或大于第 19 处)且至少有 1 个数据 ( 应位于第 19 或小于第 19 处)。此时,取第 19 和第 20 这两个数据的平均值作为
综上,
特别,当 $p = 0.5 $ 时,0.5 分位数 $ x_{0.5}$ 也记为 $Q_2 $ 或 $ M$,称为样本中位数,即有
易知,当 $n $ 是奇数时,中位数 $ x_{0.5}$ 就是
0.25 分位数
三、抽样分布
1. 统计量
1. 统计量的定义
定义:设 $X_1, X_2, \cdots, X_n $ 是来自总体 $ X$ 的一个样本,
2. 常用的统计量及其观察值
下面列出几个常用的统计量及其观察值。设 $X_1, X_2, \cdots, X_n $ 是来自总体 $ X
样本平均值
样本方差
样本标准差
样本
样本
3. 经验分布函数
我们还可以作出与总体分布函数 F (x) 相应的统计量——经验分布函数。它的作法如下:
设 $X_1, X_2, \ldots, X_n $ 是总体 $ F$ 的一个样本,用 S (x) 表示 $X_1, X_2, \ldots, X_n $ 中不大于 $ x$ 的随机变量的个数。定义经验分布函数
对于一个样本值,经验分布函数
- 设总体 $F $ 具有一个样本值 $ 1, 2, 3 $,则经验分布函数 $ F_3 (x)$ 的观察值为:
- 设总体 $F $ 具有一个样本值 $ 1, 2, 2 $,则经验分布函数 $ F_3 (x)$ 的观察值为:
一般,设 $x_1, x_2, \ldots, x_n $ 是总体 $ F$ 的一个容量为 $n $ 的样本值。先将 $ x_1, x_2, \ldots, x_n$ 按自小到大的次序排列,并重新编号,设为
对于经验分布函数
因此,对于任一实数 $x $,当 $ n$ 充分大时,经验分布函数的任一个观察值
这里的
是“上确界”(supremum)的缩写。在数学中,给定一个集合 ,该集合的上确界是所有上界中最小的一个。换句话说,$\sup S $ 是 $ S$ 的最小上界。 在这种情况下,
表示在所有 上, 的最大值。这个值用于描述 和 F(x) 之间的最大差异。因此,整个表达式 意味着当样本量 $n $ 趋于无穷大时,经验分布函数 $ F_n(x)$ 与总体分布函数 F(x) 的最大差异趋于零。
2. 常用的抽样分布统计量
考纲摘要:了解 $\chi^2 $ 分布、$ t$ 分布和 $F $ 分布的概念及性质,了解上侧 $ a$ 分位数的概念并会查表计算
1.
设
为服从自由度为
其图像如下所示:
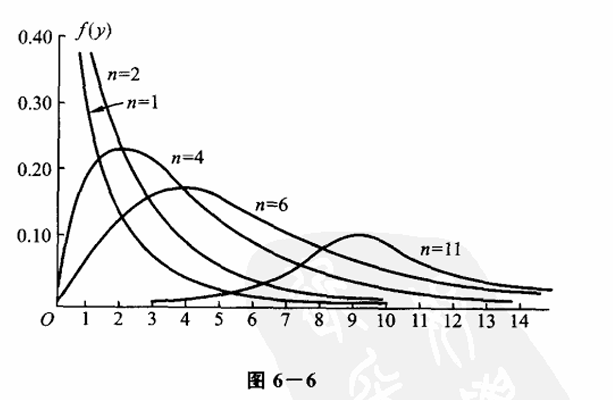
$\chi^2 $ 分布的分位点:对于给定的 $ 0<\alpha<1$,称满足条件
的点
在 40 及以下时,查表 充分大时,近似的有 $\chi_\alpha^2 (n)\approx\cfrac12 (z_\alpha+\sqrt{2n-1})^2 $,在 $ n>40$ 时可采用该近似式
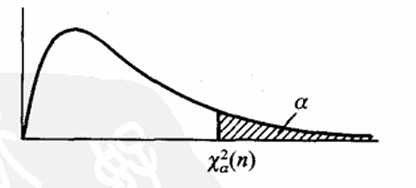
应该是一个与 有关的常数
2.
设
为服从自由度为 $n $ 的 $ t$ 分布,记作
其图像如下所示:
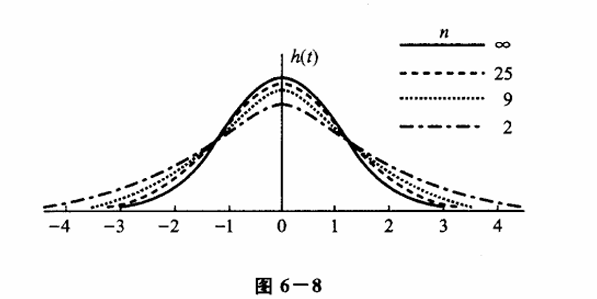
$t $ 分布概率密度函数的图像是关于 $ t=0$ 轴对称的。此外,由于
也就是说,当 $n $ 足够大时,$ t$ 分布的近似于 N (0,1) 分布
$t $ 分布的分位点:对于给定的 $ 0<\alpha<1$,称满足条件
的点
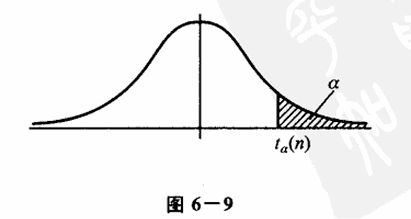
3.
设
其概率密度为:
其图像如下:
$F $ 分布的分位点,对于给定的 $ 0<\alpha<1$,称满足条件
的点
4. 正态总体的样本均值与样本方差的分布
考纲摘要:了解正态总体的常用抽样分布
设总体
当
(1) 定理一
设 $X_1, X_2, \ldots, X_n $ 是来自正态总体 $ N (\mu, \sigma^2)$ 的样本,样本均值为
(2) 定理二
设 $X_1, X_2, \ldots, X_n $ 是来自总体 $ N (\mu, \sigma^2)$ 的样本,
并且
(3) 定理三
设 $X_1, X_2, \ldots, X_n $ 是来自总体 $ N (\mu, \sigma^2)$ 的样本,
(4) 定理四
设
分别是这两个样本的样本均值;并且
分别是这两个样本的样本方差,则有
当
其中